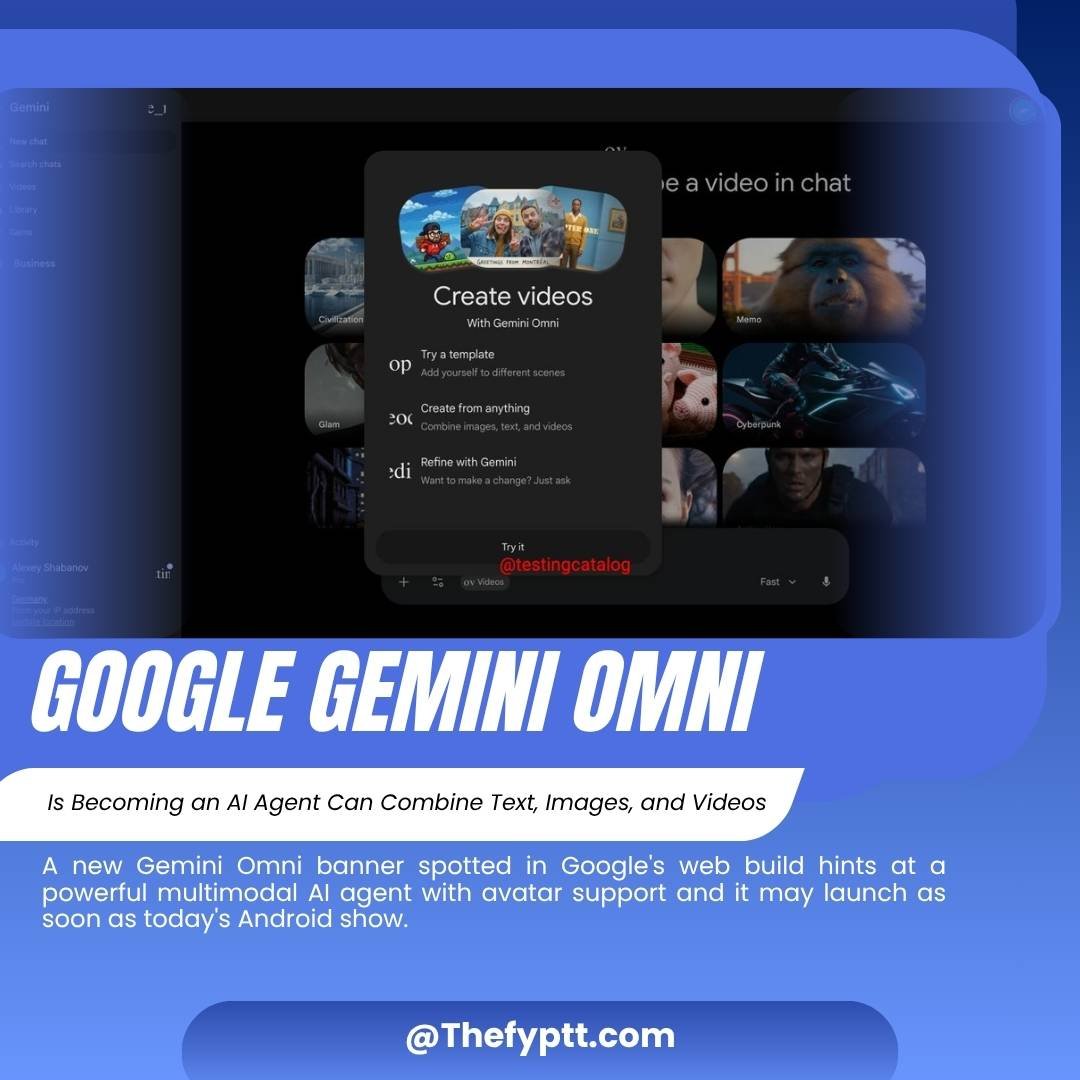
A new Gemini Omni banner spotted in Google’s web build hints at a powerful multimodal AI agent with avatar support and it may launch as soon as today’s Android show.
Google appears to be quietly building something significant inside Gemini. A newly discovered banner in Google’s web build reveals a feature called Gemini Omni and based on what’s been spotted, it looks like a full-fledged multimodal AI agent capable of working across text, images, and video simultaneously.
What is Gemini Omni?
Gemini Omni is shaping up to be more than just a chatbot upgrade. According to the leaked banner details, it will operate as an AI agent meaning it can take actions, combine multiple media types, and work more autonomously than traditional AI assistants.
The three core capabilities revealed so far:
Text
Conversational AI responses
Images
Visual understanding & creation
Videos
Video generation & editing
AI Avatars and the “Likeness” feature
One of the most intriguing aspects of Gemini Omni is its connection to AI Avatars, also known as the Likeness feature. This will allow users to insert themselves into different scenes essentially placing a digital version of yourself inside AI-generated content.
Google has already announced that AI Avatars are coming to Gemini, and Gemini Omni is expected to be deeply integrated with this capability. The Likeness feature is anticipated to be strongly tied to mobile apps, working similarly to how the feature operated on Sora, OpenAI’s video generation platform.
“Gemini Omni will be an Agent that can combine text, images, and videos. Users will be able to add themselves to different scenes.”
Could it launch at today’s Android show?
The timing of this discovery is notable. The banner was spotted just ahead of Google’s Android show raising the possibility that Gemini Omni could be officially announced or even launched during the event. While nothing is confirmed, the fact that it already appears in the live web build suggests it is very close to a public release.
Why this matters
If Gemini Omni lives up to what the leaked banner suggests, it would represent a major leap for Google’s AI ambitions. Most current AI tools handle text, image, or video in isolation. A true multimodal agent that combines all three while also letting users place themselves into generated scenes would put Google in direct competition with OpenAI’s Sora and other advanced generative AI platforms.
We will be watching the Android show closely. Stay tuned to thefyptt.com for updates as they happen.